Picking the right LLM for your enterprise AI stack shouldn't feel like guesswork. But with so many models, it's hard to know where things stand. That's why we built the StackAI LLM Leaderboard, and today we're relaunching it with more models, more metrics, and new ways to compare what actually matters to your team.
Here's everything that's live now.
All the models, in one place
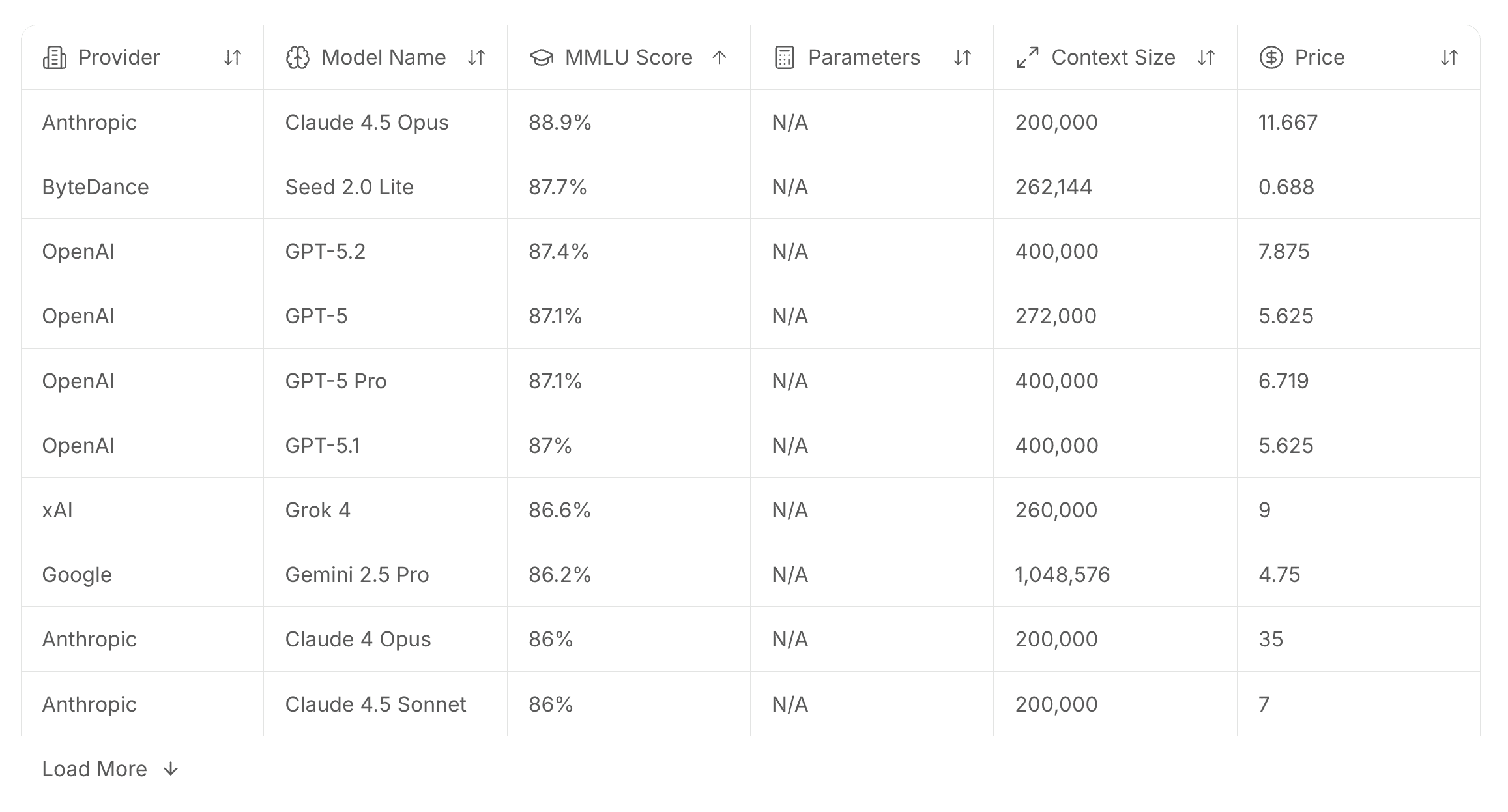
The full leaderboard gives you a sortable, browsable table of models across every major provider: Anthropic, OpenAI, Google, Amazon, Meta, Cohere, Mistral, and more. Filter and sort by MMLU score, parameters, context size, and price per million tokens. No more hunting across provider docs to piece together a comparison.
Six benchmark categories covered

We track performance across the benchmarks that matter most for enterprise use cases.
MMLU tests general knowledge breadth across 57 subjects including math, history, law, and medicine. HumanEval+ measures code quality across complex, multi-language programming challenges. GPQA evaluates graduate-level reasoning in specialized domains. MT-Bench tests multi-turn conversation, reasoning, and instruction-following. SWE Benchmarks cover software engineering tasks like code generation, debugging, and algorithm design. GSM8K targets multi-step math reasoning and logical problem-solving.
Top model rankings by what you care about

Beyond the full table, we've surfaced curated rankings so you can cut straight to the answer. Top models by MMLU score (Claude 4.5 Opus is currently leading at 88.9%). Fastest models by throughput — Mercury 2 from Inception is clocking 870.9 tokens per second. Most cost-effective models by price per million tokens, with Gemma 3n E4B currently at the top. Longest context windows, led by Grok 4 Fast and Grok 4 Heavy at 2 million tokens each.
A live token speed visualizer

New to this refresh: an interactive demo that shows you what different token generation speeds actually feel like in real time. 1,200 t/s versus 200 t/s versus 40 t/s. It's one thing to read the number, it's another to watch it.
Side-by-side model comparison
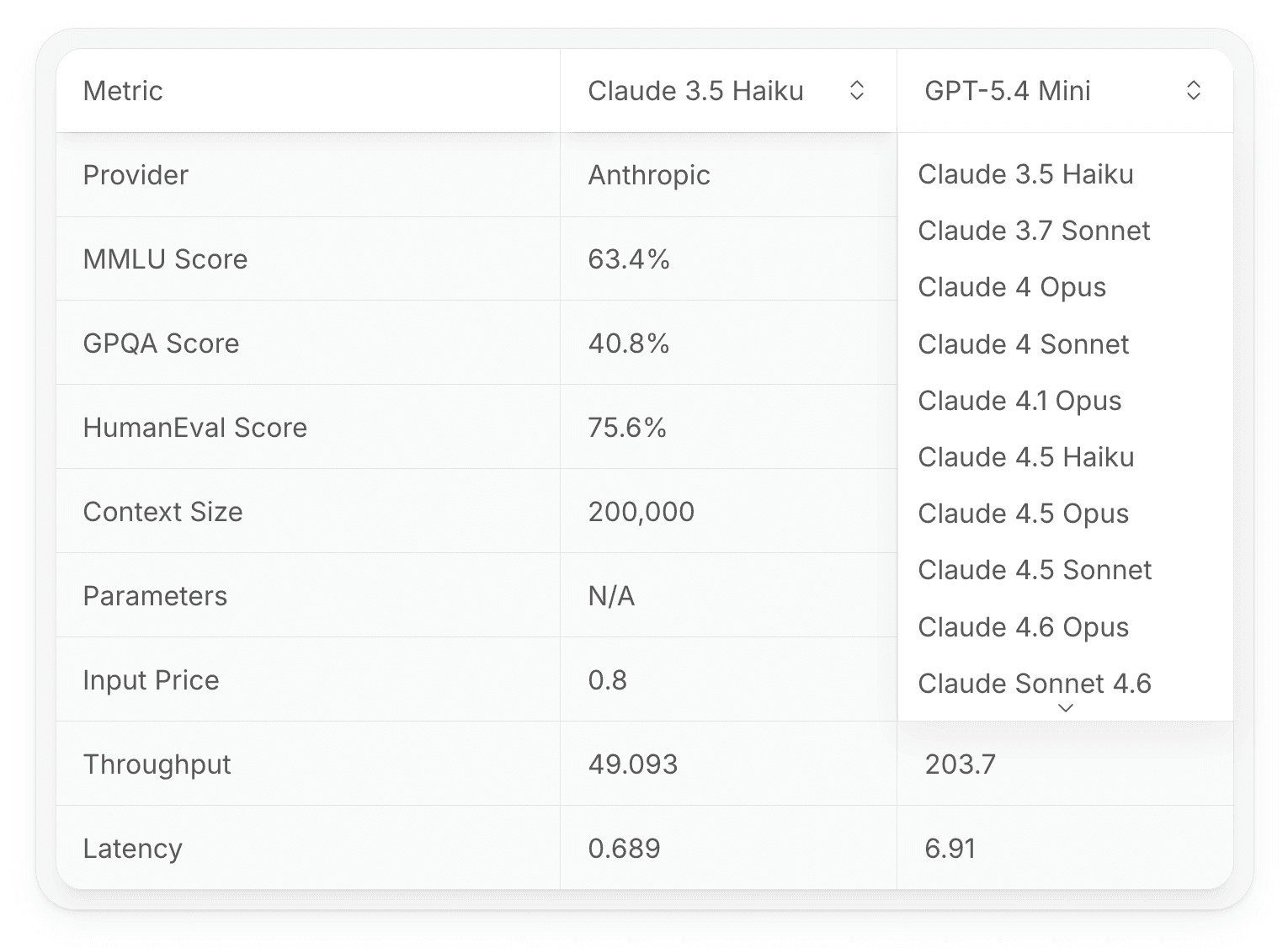
You can now compare any two models head-to-head across every metric we track: MMLU, GPQA, HumanEval, DROP, context size, parameters, input price, output price, inference speed, throughput, and latency. Pick your models, see the full picture.
Why we built this
Choosing the wrong model can be expensive, both in compute costs and in outcomes. Whether you're optimizing for accuracy, speed, cost, or context length, the answer is different depending on your use case. The StackAI LLM Leaderboard is designed to make that decision faster and more informed, so you can spend less time evaluating and more time building.
Check it out today at stackai.com/llm-leaderboard.

Stefano Malavasi
Growth at StackAI

